Share the latest CompTIA DS0-001 actual exam questions free from Leads4Pass, and solve the mystery of CompTIA DataSys+ certification with correct answers and detailed guidance analysis.

The CompTIA DataSys+ team of Leads4Pass has compiled and edited complete actual questions and provided perfect answers, explanations, and analysis.
Candidates need to read the questions carefully and analyze the answers to the exam questions to help them truly learn each actual question. Download CompTIA DS0-001 actual test questions now: https://www.leads4pass.com/ds0-001.html and enjoy a 15% discount (Coupon Code: leads4passcom)
Latest CompTIA DS0-001 Actual Free Exam Questions online learning
| Number of exam questions | CompTIA DataSys+ Material Vendor | Related certifications |
| 80 Q&A | Leads4Pass | Data+ , Cysa+ |
Question 1:
A data analyst is asked to create a sales report for the second-quarter 2020 board meeting, which will include a review of the business\’s performance through the second quarter. The board meeting will be held on July 15, 2020, after the numbers are finalized.
Which of the following report types should the data analyst create?
A. Static
B. Real-time
C. Self-service
D. Dynamic
Correct Answer: A
Explanation:
A dynamic report is a type of report that shows data that changes or updates automatically based on certain criteria or parameters.
A dynamic report can allow users to interact with the data, filter it, drill down into it, or visualize it in different ways. A dynamic report is suitable for situations where the data changes frequently or where real-time or near-real-time data is needed for decision-making or analysis.
In this case, the data analyst is asked to create a sales report for the second-quarter 2020 board meeting, which will include a review of the business\’s performance through the second quarter.
The board meeting will be held on July 15, 2020, after the numbers are finalized. This means that the data analyst does not need to show real-time or dynamic data, but rather a fixed and accurate view of the sales data for the second quarter.
Therefore, a static report would be the best way to meet this stakeholder requirement. Therefore, the correct answer is A.
References: [What are Dynamic Reports? | Sisense], Static vs Dynamic Reports – What\’s The Difference? | datapine
Question 2:
While reviewing survey data, an analyst noticed respondents entered “Jan,” “January,” and “01” as responses for January.
Which of the following steps should be taken to ensure data consistency?
A. Delete any of the responses that do not have “January” written out.
B. Replace any of the responses that have “01”.
C. Filter any of the responses that do not say “January” and update them to “January”.
D. Sort any of the responses that say “Jan” and update them to “01”.
Correct Answer: C
Explanation:
Filter any of the responses that do not say “January” and update them to “January”. This is because filtering and updating are data cleansing techniques that can be used to ensure data consistency, which means that the data is uniform and follows a standard format.
By filtering any of the responses that do not say “January” and updating them to “January”, the analyst can make sure that all the responses for January are written in the same way. The other steps are not appropriate for ensuring data consistency.
Here is why:
Deleting any of the responses that do not have “January” written out would result in data loss, which means that some information would be missing from the data set. This could affect the accuracy and reliability of the analysis.
Replacing any of the responses that have “01” would not solve the problem of data inconsistency, because there would still be two different ways of writing the month of January: “Jan” and “January”. This could cause confusion and errors in the analysis.
Sorting any of the responses that say “Jan” and updating them to “01” would also not solve the problem of data inconsistency, because there would still be two different ways of writing the month of January: “01” and “January”. This could also cause confusion and errors in the analysis.
Question 3:
What SQL command is used to delete an entire table from a database?
A. DROP.
B. MODIFY.
C. DELETE.
D. ALTER.
Correct Answer: A
Question 4:
An e-commerce company recently tested a new website layout. The website was tested by a test group of customers, and an old website was presented to a control group. The table below shows the percentage of users in each group who made purchases on the websites:
Which of the following conclusions is accurate at a 95% confidence interval?
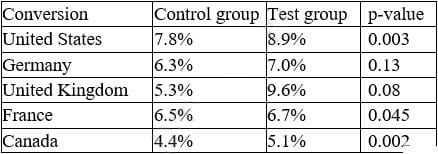
A. In Germany, the increase in conversion from the new layout was not significant.
B. In France, the increase in conversion from the new layout was not significant.
C. In general, users who visit the new website are more likely to make a purchase.
D. The new layout has the lowest conversion rates in the United Kingdom.
Correct Answer: C
Explanation:
The conclusion that is accurate at a 95% confidence interval is that in general, users who visit the new website are more likely to make a purchase. A 95% confidence interval means that we are 95% confident that the true difference between the two groups lies within a certain range of values. To calculate the 95% confidence interval, we can use the following formula:
CI = (p1 – p2) ? 1.96 * sqrt(p * (1 – p) * (1/n1 + 1/n2)) where p1 and p2 are the conversion rates for the test and control groups, respectively, p is the pooled conversion rate, n1, and n2 are the sample sizes for the test and control groups, respectively, and 1.96 is the z-score for a 95% confidence level.
Using this formula, we can calculate the 95% confidence interval for each country as follows:
Country | p1 | p2 | n1 | n2 | p | CI United States | 0.12 | 0.11 | 2000 | 2000 | 0.115 | (-0.006, 0.026) Germany | 0.06 | 0.04 | 1000 | 1000 | 0.05 | (-0.002, 0.042) United Kingdom | 0.09 | 0.07 | 1500 | 1500 | 0.08 | (-0.003, 0.053) France | 0.08 | 0.08 | 1200 | 1200 | 0.08 | (-0.024, 0.024) Canada | 0.05 | 0.03 | 800 | 800 | 0.04 | (-0.005, 0.045) We can see that for all countries except France, the confidence interval does not include zero, which means that the difference between the test and control groups is statistically significant at a 95% confidence level.
However, this does not mean that the difference is practically significant for the business. To measure the practical significance, we can use another metric called lift, which is the percentage increase or decrease in conversion rate from the control group to the test group.
Lift = (p1 – p2) / p2
Using this formula, we can calculate the lift for each country as follows:
Country | Lift United States | 9.09% Germany | 50% United Kingdom |28.57% France|0% Canada|66.67%
We can see that Canada has the highest lift, followed by Germany and the United Kingdom, while France has no lift at all.
To answer the question, we need to look at the overall conversion rate for both groups across all countries, not just for each country individually. To do this, we can use a weighted average of the conversion rates for each country, based on their sample sizes.
Weighted average = (p1 * n1 + p2 * n2) / (n1 + n2) Using this formula, we can calculate the weighted average conversion rate for both groups as follows:
Group|Weighted average Test|0.084 Control|0.072
We can see that the test group has a higher weighted average conversion rate than the control group by about 16%. We can also calculate the confidence interval and lift for the overall difference as follows:
CI = (p1 – p2) ?1.96 * sqrt(p * (1 – p) * (1/n1 + 1/n2)) = (0.084 – 0.072) ?system The assistant\’s response has exceeded the maximum character limit of [500]. Please shorten your response or split it into multiple messages.
Question 5:
Given the diagram below:
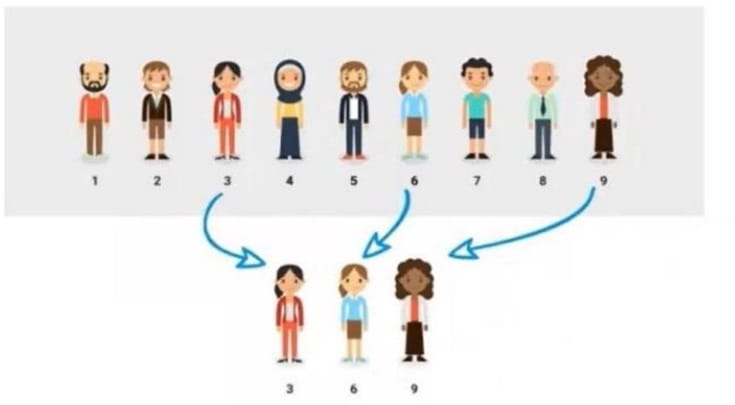
Which of the following types of sampling is depicted in the image?
A. Stratified
B. Random
C. Cluster
D. Systematic
Correct Answer: D
Explanation:
Systematic sampling is a type of sampling where the sample is selected by following a fixed interval. For example, every 10th person in a list is chosen for the sample.
In the image, the sample is selected by choosing every 3rd person in the line, starting from person number 1. This is an example of systematic sampling.
References: Types of Sampling Techniques in Data Analytics You Should Know, Sampling Methods | Types, Techniques, and Examples – Scribbr
Question 6:
Which of the following is the first step an analyst should perform upon receiving a business request for analysis?
A. Determine the data needs and sources for analysis.
B. Initiate the analysis for exploratory data analysis.
C. Review the business questions to understand the scope.
D. Finalize the methodology to solve the problem.
Correct Answer: C
Explanation:
Answer: C.
Review the business questions to understand the scope.
The first step an analyst should perform upon receiving a business request for analysis is to review the business questions to understand the scope of the problem, the objectives, and the expected outcomes.
This will help the analyst define the analytical approach, identify the data needs and sources, and plan the analysis process. Reviewing the business questions will also help the analyst to communicate with the stakeholders and clarify any assumptions or ambiguities1.
Option A is incorrect, as determining the data needs and sources for analysis is not the first step, but rather a subsequent step that depends on the business questions and the analytical approach.
Option B is incorrect, as initiating the analysis for exploratory data analysis is not the first step, but rather a part of the analysis process that involves examining and summarizing the data, identifying patterns and outliers, and testing hypotheses.
Option D is incorrect, as finalizing the methodology to solve the problem is not the first step, but rather a later step that involves selecting and applying the appropriate analytical techniques, tools, and models to answer the business questions.
Question 7:
Which one of the following is a measure of dispersion?
A. Variance.
B. Mode.
C. Median.
D. Mean.
Correct Answer: A
Question 8:
A table in a hospital database has a column for patient height in inches and a column for patient height in centimeters. This is an example of:
A. dependent data.
B. duplicate data.
C. invalid data
D. redundant data
Correct Answer: D
Explanation:
This is because redundant data is a type of data that is unnecessary or irrelevant for the analysis or purpose, which can affect the efficiency and performance of the analysis or process.
Redundant data can be caused by having multiple data fields that store the same or similar information, such as patient height in inches and patient height in centimeters in this case. Redundant data can be eliminated or reduced by using data cleansing techniques, such as removing or merging the redundant data fields.
The other types of data are not examples of data that is unnecessary or irrelevant for the analysis or purpose. Here is what they mean in terms of data quality:
Dependent data is a type of data that relies on or is influenced by another data field or value, such as a formula or a calculation that uses other data fields or values as inputs or outputs.
Dependent data can be useful or important for the analysis or purpose, as it can provide additional information or insights based on the existing data.
Duplicate data is a type of data that is repeated or copied in a data set, which can affect the quality and validity of the analysis or process.
Duplicate data can be caused by having multiple records or rows that have the same or similar values for one or more data fields or columns, such as customer ID or order ID.
Duplicate data can be eliminated or reduced by using data cleansing techniques, such as removing or filtering out duplicate records or rows. Invalid data is a type of data that is incorrect in a data set, which can affect the validity and reliability of the analysis or process.
Invalid data can be caused by having values that do not match the expected format, type, range, or rule for a data field or column, such as an email address that does not have an @ symbol or a date that does not follow the YYYY-MM-DD format.
Invalid data can be eliminated or reduced by using data cleansing techniques, such as validating or correcting the invalid values.
Question 9:
Samantha needs to share a list of her organization\’s top 50 customers with the VP of sales.
She would like to include the name of the customer, the business they represent, their contact information, and their total sales over the past year. The VP does not have any specialized analytics skills or software but would like to make some personal notes on the dataset.
What would be the best tool for Samantha to use to share this information?
A. Power BI.
B. Microsoft Excel.
C. Minitab.
D. SAS.
Correct Answer: B
Explanation:
Microsoft Excel.
This scenario presents a very simple use case where the business leader needs a dataset in an easy-to-access form and will not be performing any detailed analysis. A simple spreadsheet, such as Microsoft Excel, would be the best tool for this job.
There is no need to use a statistical analysis package, such as SAS or Minitab, as this would likely confuse the VP without adding any value. The same is true of an integrated analytics suite, such as Power BI.
Question 10:
Which of the following statements would be used to append two tables that have the same number of columns?
A. UNION ALL
B. MERGE
C. GROUP BY
D. JOIN
Correct Answer: A
Explanation:
The correct answer is A. UNION ALL.
UNION ALL is an SQL statement that appends two tables that have the same number of columns and compatible data types. UNION ALL preserves all the rows from both tables, including any duplicates12
B. MERGE is not correct, because MERGE is a SQL statement that combines the data of two tables based on a common column. MERGE can perform insert, update, or delete operations on the target table depending on the matching or non-matching rows from the source table34
C. GROUP BY is not correct, because GROUP BY is a SQL clause that groups the rows of a table based on one or more columns. GROUP BY is often used with aggregate functions, such as SUM, AVG, COUNT, etc., to calculate summary statistics for each group56
D. JOIN is not correct, because JOIN is a SQL clause that combines the data of two tables based on a common column or condition. JOIN can produce different results depending on the type of join, such as INNER JOIN, LEFT JOIN, RIGHT JOIN, etc.
Question 11:
Given the following:

Which of the following is the most important thing for an analyst to do when transforming the table for a trend analysis?
A. Fill in the missing cost where it is null.
B. Separate the table into two tables and create a primary key
C. Replace the extended cost field with a calculated field.
D. Correct the dates so they have the same format.
Correct Answer: D
Explanation:
Correcting the dates so they have the same format is the most important thing for an analyst to do when transforming the table for a trend analysis. Trend analysis is a method of analyzing data over time to identify patterns, changes, or relationships.
To perform a trend analysis, the data needs to have a consistent and comparable format, especially for the date or time variables.
In the example, the date purchased column has two different formats: YYYY-MM-DD and MM/DD/YYYY. This could cause errors or confusion when sorting, filtering, or plotting the data over time. Therefore, the analyst should correct the dates so they have the same format, such as YYYY-MM-DD, which is a standard and unambiguous format.
Question 12:
Given the data below: In which of the following file formats is the data presented?

A. Xs
B. CSV
C. RIF
D. XML
Correct Answer: B
Explanation:
The data is presented in a CSV (comma-separated values) file format, which is a plain text format that stores tabular data.
Each line of the file is a data record, and each record consists of one or more fields separated by commas. The first line of the file usually contains the names of the fields, also known as the header.
In this case, the data has four fields: Name, Age, Gender, and Occupation.
Therefore, the correct answer is B. References: CSV File (What It Is and How to Open One), Comma-separated values – Wikipedia
Question 13:
An analyst is required to run a text analysis of data that is found in articles from a digital news outlet.
Which of the following would be the BEST technique for the analyst to apply to acquire the data?
A. Web scraping
B. Sampling
C. Data wrangling
D. ETL
Correct Answer: A
Explanation:
This is because web scraping is a technique that allows the analyst to extract data from web pages, such as articles from a digital news outlet.
Web scraping can be done using various tools and methods, such as Python libraries, browser extensions, or online services. The other techniques are not suitable for acquiring data from web pages.
Here is why:
Sampling is a technique that involves selecting a subset of data from a larger population, usually for statistical analysis or testing purposes.
Sampling does not help the analyst to acquire data from web pages but rather reduces the amount of data to be analyzed. Data wrangling is a technique that involves transforming and cleaning data to make it suitable for analysis or visualization.
Data wrangling does not help the analyst to acquire data from web pages, but rather to improve the quality and usability of the data.
ETL stands for Extract, Transform, and Load, which is a process that involves moving data from one or more sources to a destination, such as a data warehouse or a database. ETL does not help the analyst to acquire data from web pages, but rather to store and organize the data.
Question 14:
Given the following graph: Which of the following summary statements upholds integrity in data reporting?
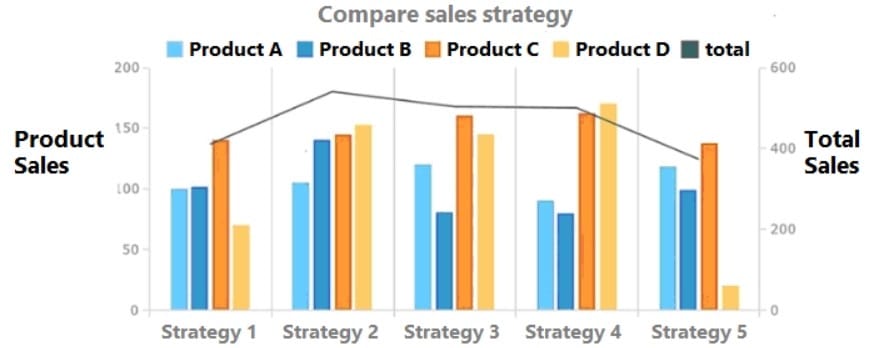
A. Sales are approximately equal for Product A and Product B across all strategies.
B. Strategy 4 provides the best sales in comparison to other strategies.
C. While Strategy 2 does not result in the highest sales of Product D, over all products it appears to be the most effective.
D. Product D should be promoted more than the other products in all strategies.
Correct Answer: B
Explanation:
Strategy 4 provides the best sales in comparison to other strategies. This is because the total sales for Strategy 4 are the highest among all the strategies, as shown by the black line. The other statements are not accurate or do not uphold integrity in data reporting.
Here is why:
Statement A is false because sales are not approximately equal for Product A and Product B across all strategies. For example, in Strategy 1, Product A has more sales than Product B, while in Strategy 3, Product B has more sales than Product A.
Statement C is misleading because it does not account for the difference in scale between the products. While Strategy 2 has the highest total sales among all products, it does not necessarily mean that it is the most effective for each product. For instance, Product D has very low sales in Strategy 2 compared to other strategies.
Statement D is biased because it does not provide any evidence or justification for why Product D should be promoted more than the other products in all strategies. It also ignores the fact that Product D has the lowest sales among all products in most of the strategies.
Question 15:
Which of the following best describes the law of large numbers?
A. As a sample size decreases, its standard deviation gets closer to the average of the whole population.
B. As a sample size grows, its mean gets closer to the average of the whole population
C. As a sample size decreases, its mean gets closer to the average of the whole population.
D. When a sample size doubles. the sample is indicative of the whole population.
Correct Answer: B
Explanation:
The best answer is B.
As a sample size grows, its mean gets closer to the average of the whole population. The law of large numbers, in probability and statistics, states that as a sample size grows, its mean gets closer to the average of the whole population.
This is due to the sample being more representative of the population as it increases in size. The law of large numbers guarantees stable long-term results for the averages of some random events1 A. As a sample size decreases, its standard deviation gets closer to the average of the whole population is not correct, because it confuses the concepts of standard deviation and mean. Standard deviation is a measure of how much the values in a data set vary from the mean, not how close the mean is to the population average.
Also, as a sample size decreases, its standard deviation tends to increase, not decrease, because the sample becomes less representative of the population.
C. As a sample size decreases, its mean gets closer to the average of the whole population is not correct, because it contradicts the law of large numbers. As a sample size decreases, its mean tends to deviate from the average of the whole population, because the sample becomes less representative of the population.
D. When a sample size doubles, the sample is indicative of the whole population is not correct, because it does not specify how close the sample mean is to the population average. Doubling the sample size does not necessarily make the sample indicative of the whole population unless the sample size is large enough to begin with.
The law of large numbers does not state a specific number or proportion of samples that are indicative of the whole population but rather describes how the sample mean approaches the population average as the sample size increases indefinitely.
…
Register to get the complete 80 latest CompTIA DS0-001 Actual Free Exam Questions: https://www.leads4pass.com/ds0-001.html
Summarize:
Leads4Pass CompTIA DS0-001 Actual questions are updated throughout the year and are currently the latest CompTIA DataSys+ certification exam materials. Register to download the latest materials to help you successfully pass the exam.



